
As you all know, data is very important for a business.
- Your business decisions are based on charts generated by data.
- Your machine learning/AI can’t be built without data.
- You are selling your personal data to use “free” software.
- Scraping/crawling data is a modern job
As a Software Engineer, you have to deal with data in your career and your success depends on how big the data that your software can deal with?
In this post, I would like to share my experience with a problem that looked simple at first but turned out to be more interesting because the data we dealt with was huge.
Simple problem
We started with a simple problem – build an application as per the below diagram.

Very simple, right? That’s what we thought when received the requirement, but we were wrong…
Huge Data
We completed a simple Go application and sent it to my boss very quickly. After that, he said: “Good job, please help me use the application to download this dataset and you guys should complete it in 7 days”. And you know what? The dataset was about 2 billion records of URLs.
Let’s do some math to see how long it would take for us to complete all of the 2 billion URLs?
My assumption was the application needed 2 seconds (0.5 URL/s) to complete 4 steps (download image => process image => face detection => save result). So we would have needed:
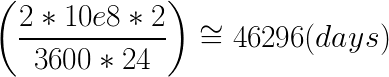
I think you can imagine what happened if I had told my boss that we needed more than 127 years to complete 2 billion URLs, right? Our boss would have said, “Ok I can wait!”

Luckily, we didn’t. Instead, we tried to relax and found a better solution to make my boss happy 😉
High concurrency problems
The goal was to complete 2 billion URLs in 7 days. So another math:
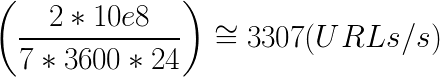
We needed to build a system that can complete (download, process, face detect, save the result) 3307 URLs per second.
To increase the concurrency we need to solve these problems:
- What are the ways that help increase concurrency?
- Data is important, how to keep the data safe and consistent?
- What happens when the system fails?
- How to monitor the system for tuning (database, services,…)?
- What is the cost to implement the system?
Ways to increase concurrency
Basically, there are 2 ways we can do to increase concurrency:
- Increase hardware resources like CPU, RAM, I/O speed aka Scale Up
- Scale-out (based on the scale-cube):
- Splitting by functions (Y-Axis)
- Cloning to multiple processes (X-Axis)
- Data partitioning (Z-Axis)
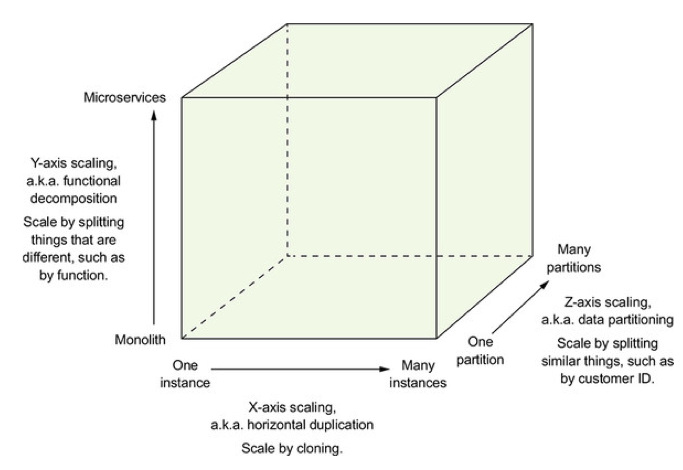
We were thinking about them and below was our brainstorm.
Increase hardware resources (scale-up)
Scale-up is usually chosen approach when it comes to increasing concurrency. This approach usually doesn’t require any code changes so it won’t break any existing functions of the app and can be applied very quickly.
However, scale-up only works if there are no performance issues or bottlenecks in your application code and the hardware resources can still meet your application needs.

Scale-out by cloning (aka X-axis)
Increase concurrency by cloning a single application node to multiple nodes is one of the popular approaches. It helps us break through the limitation of hardware resources, separate failures and lower infrastructure,…
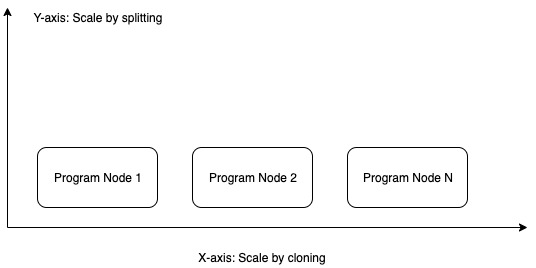
We wanted to use this approach. But let’s dive deeper to see if we can use the scale-out by Y-Axis also?
Scale-out by splitting (aka Y-axis)
For the Y-axis, we needed to review the workflow diagram of the application to see if we can split any functions and what is the advantage?
Fortunately, we quickly recognized the Face Detection function can run faster on GPU and also have the advantage of multiple technology stacks, in this case, we can use Python for Face Detection instead of Golang.
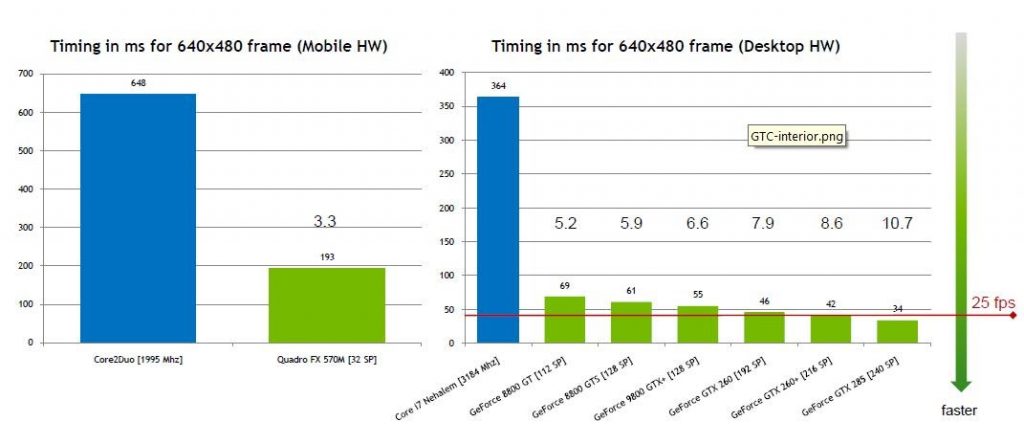
Now we can combine 2 scale-out methods and it looks like the chart below.
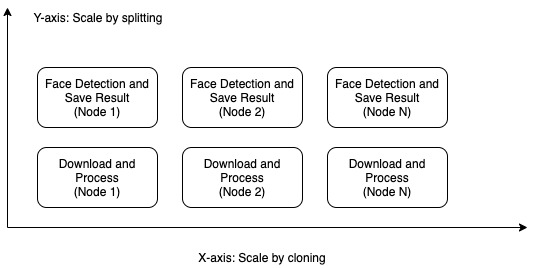
We were happy with the scaling out approaches above. However, scale-out requires more complex architecture than the scale-up one and we need to consider data consistency as well as the Race Condition problem. We will talk more about it in the “Race Condition and Data Duplication” section.
Distributed Race Condition
When you write code which needs to work in a multithreading condition, you must consider the Race Condition problem.

How Race Condition problem can happen in our system if we scale-out by X-axis and Y-axis?
- The nodes can pick the same URL to process because they can run in parallel.
- If multiple nodes pick the same URL, the result of one URL can be interleaved. (The same face can have multiple coordinates in the image).
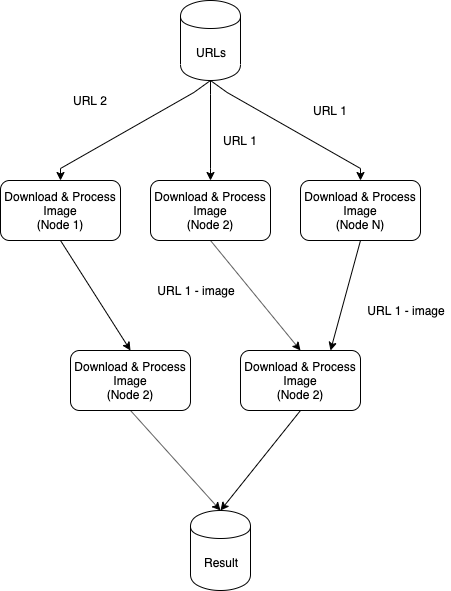
The Race Condition causes the below issues:
- Waste of resources
- Faking concurrency
- Data corruption
So, how we solve the Race Condition problem?
We realized the real problem was how a “Download & Process image” node can pick a unique URL? Therefore the unique message will be sent to Face Detection nodes and the result won’t be duplicated.

There are 3 ways to pick a unique URL from URLs database:
Distributed locks
- Pro:
- N/a
- Con:
- Pessimistic locking impact performance
- Hard to apply because we need to synchronize multiples nodes
Queue
- Pros
- Easy to apply
- Should not impact performance with High Concurrency Queue
- Cons
- The Load concentrates on the queue so it can become a bottleneck.
Data sharding (Z-axis)
- Pro:
- High performance because of share load
- Con:
- Hard to apply (need to find a way to shard data, scaling…)
My team preferred Queue and Data Sharding to Locking Mechanism because we wanted the best performance. But how can we archive it?
There is another problem which we should think about before providing a solution and I think it is very important in any distributed system. The problem is Fault-tolerance.
Fault-tolerance
Whenever we design a system we always think about fault-tolerance of our system.
- What happens when the node(s) crash?
- What happens with the data when we restart the node? or bootstrap a new one?
- How can failure happen in our system?

High Concurrency Approaches
We decided that our system needs to follow these scaling approaches:
- Need to scale out by cloning to multiple nodes. For example, we need 10 nodes (just an example) of the “download & process image” to have concurrency > 3307 URLs/s.
- Need to scale out by splitting functions. For example. “Face Detection” should run in a machine that has a powerful GPU.
- Need to shard data or apply a Queue to make sure each node picks a unique URL to process and it can do in parallel without locking (prevent Race Condition issue).
Point (1) & (2) are easy to apply but how we shard data (3) is the problem we need to solve.
Based on experience, our team listed out 3 approaches and this was how we selected the right approach for our problem.
Approach 1: Range Based Sharding
Range Based Sharding is a method that shard one large table to multiple tables (partitions) based on a range of special value.
Our URLs table looks like below
| ID | URL | Done |
| 1 | http://abc.com/image.jpeg | 1 |
| 2 | http://abc.com/image2.jpeg | 0 |
| 3 | http://abc.com/image3.jpeg | 0 |
| 4 | http://abc.com/image4.jpeg | 0 |
| 5 | http://abc.com/image5.jpeg | 0 |
Because the value of the ID column is a unique ascending number so we can apply Range Based Sharding on the ID column.
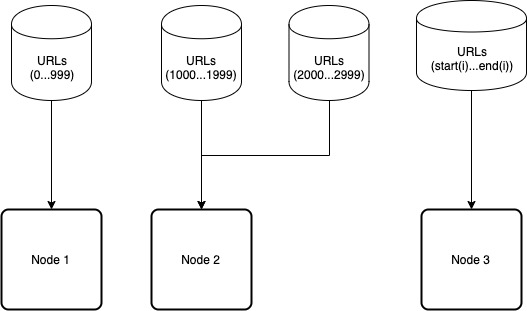
As you can see in the diagram above, we can shard a single table to multiple tables and we will assign a table (or multiple tables) to a node for processing.
In each node, we need to build a simple worker queue to process URLs in multiple goroutines. It helps us increase the concurrency of each node.
We needed the ability to change the number of partitions quickly because we needed to measure the performance of a node then adjust the number of partitions to maximize resource-usage to optimize cost. So, we built a mechanism to change range based on the number of partitions we wanted to split.

This approach not only helped us solve Race Condition but also the performance was good because it is a non-locking and distributed load for DB by separating I/O.
However, there are some tradeoffs:
- Cost for preparation and deployment is high
- Hard for scaling.
- Add a new node: We can’t assign a new node to an existing partition. So we need to re-shard data and start again with new partitions number.
- Remove a node (a node crash): The partition of this node can be abandoned.
Approach 2: Key Based Sharding (Logical)
In the previous approach, we must shard on a table to multiple tables and it takes preparation time. So, we thought about an approach that we don’t need to shard the table physically. Because the only real problem we needed to solve was how a node picks a URL that has never been picked by any other node.
The ID of a URL is a unique ascending number so we can base on it to pick the URL.
| ID | URL | Done |
| 1 | http://abc.com/image.jpeg | 1 |
| 2 | http://abc.com/image2.jpeg | 0 |
| 3 | http://abc.com/image3.jpeg | 0 |
| 4 | http://abc.com/image4.jpeg | 0 |
| 5 | http://abc.com/image5.jpeg | 0 |
In each node, we need to generate the ID of a URL and use that ID to query the database to get the URL. So we need a mechanism to generate a unique ascending ID in each node. Below was the mechanism we built

With this approach, we do not need to prepare the data or re-generate the data, it is also non-locking so the performance will be good.
The tradeoffs of this approach:
- The load is concentrated on a single database so the database can become the bottleneck (we can solve this problem by using more hardware resources for database node)
- Hard for scaling:
- Remove a node (or node crash): We need to recover the node (or add a new one with the same id) if we don’t want the partition of the node is abandoned
- Add new node: restart all nodes in the system with new “Number Of Processes” value
- Need to maintain the number of remaining URLs (or the processed URL)
Approach 3: Worker Queue
We thought about the worker queue approach when we investigated a way for easier scaling but still has the best performance without locking and easier for fault-tolerance.
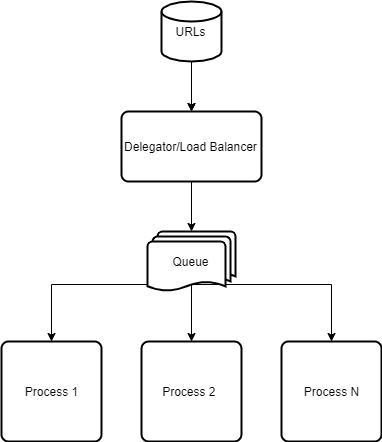
- The Delegator/Load Balancer is a service that fetches URLs from URLs database and pushes the URLs into the Queue which will be consumed by Workers (download & process image)
- Queue: an abstraction, we can build this queue inside the Delegator/Load Balancer or using an open-source project like RabbitMQ/Kafka.
- Process (1..N): Worker that consumes the URL from Queue for processing. Then push another queue item for the Face Detection phase.
With this approach, we have some advantages:
- We archive Fault-Tolerance and Scalability naturally
- When a worker fails, its URLs will be handled by other workers
- When we add a worker, it will consume outstanding URLs in the queue
- We can reuse the Queue system for Face Detection to optimize the reusable result of “Download & Process image”. This means we can save the image which was downloaded and processed in storage before putting the task item into Face Detection queue.
- The implementation of single vs multiple goroutines in a node are the same, so we can have flexibility.
The tradeoff of this approach is:
- Load concentrate on Delegator and the Queue services, therefore, we may need a way to scale them out.
We can solve the tradeoff above by scaling out the Delegator using approach 2. So the final approach follows the diagram below.
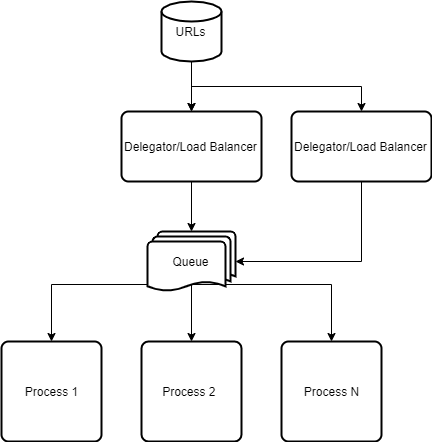
Conclusion
As you can see, the simple problem at first became very complicated with huge data. There are many approaches to solve the same problem but we must carefully evaluate them and choose the suitable one based on business needs and the scope of the problem we need to solve.
We will have another post (I hope I won’t be too busy) to benchmark the approach in practice to validate them.
Please let me know your thoughts about 3 approaches or if you have another approach please leave a comment below for discussing 😉
Reference
- Scale cube image from this post: https://medium.com/@cserkaran/the-scale-cube-d84ca0c2e900
- Face detection on GPU: https://sites.google.com/site/facedetectionongpu/